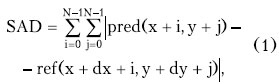|
Поиск по сайту: |
|
По базе: |
| Главная страница > Статьи > Микроконтроллеры | |||||||||
|
|
||||||
AVR32: новый микроконтроллер для мультимедийных приложенийВ современном мире растет количество приборов для обработки нетекстовой информации, включаемой в понятие мультимедиа. Мультимедийные данные обрабатываются во всех биометрических приложениях, пользовательских системах позиционирования (GPS), развлекательных приборах для повседневной жизни и прочих устройствах, которые сегодня называют мультимедийными. В данной статье рассказывается о новом аппаратном решении фирмы Atmel, ориентированном на такие задачи - микроконтроллере AP7000 c архитектурой AVR32. Введение Всё новые и новые задачи, стоящие перед мультимедийными приборами, требуют выполнения всё более сложных алгоритмов обработки мультимедийной (и не только!) информации, что увеличивает вероятность достижения предела возможностей любого встраиваемого микроконтроллера. Алгоритмы быстрого преобразования Фурье (FFT), инверсного дискретного косинусного преобразования (iDCT) и другие математически-насыщенные алгоритмы, которые редко реализовывались на встраиваемых микроконтроллерах еще несколько лет назад, становятся более востребованными сегодня. В мультимедийных системах такие алгоритмы, как правило, используются для кодирования/декодирования данных, в т.ч. форматов MP3 и MPEG-4. Это требует высокой производительности элементной базы, на которой построены указанные приборы. Исторически, задача повышения производительности решается за счет увеличения рабочей тактовой частоты процессора либо реализации многоядерных решений (ARM+DSP). По причине высокого энергопотребления такие решения могут использоваться не во всех встраиваемых системах, да и отладка двуядерных микроконтроллеров - задача не из легких. Массогабаритные характеристики портативных приборов определяются не только размерами печатной платы, но и батарей (а чем ниже энергопотребление, тем меньше и легче батарея). Рассматривая задачу в таком контексте, складываются следующие требования к микроконтроллеру:
Задачей построения микроконтроллера с перечисленными выше требованиями еще в 2001 году занялась группа разработчиков компании Atmel, которая предложила решать её не повышением тактовой частоты, а улучшением архитектуры ядра процессора, который должен выполнить максимальное количество действий за один такт. Были начаты разработки в следующих направлениях:
где (x,y) - координаты точки, (dx,dy) - смещение относительно этой точки, Ниже приведен фрагмент кода на С, написанный для выражения (1).
/* From sad.c of the open source xvid codec */
uint32_t sad = 0;
uint32_t j;
uint8_t const *ptr_cur = cur;
uint8_t const *ptr_ref = ref;
for (j = 0; j < 8; j++) {
//Compute SAD for 4 bytes
sad += ABS(ptr_cur[0] - ptr_ref[0]);
sad += ABS(ptr_cur[1] - ptr_ref[1]);
sad += ABS(ptr_cur[2] - ptr_ref[2]);
sad += ABS(ptr_cur[3] - ptr_ref[3]);
//Compute SAD for next 4 bytes
sad += ABS(ptr_cur[4] - ptr_ref[4]);
sad += ABS(ptr_cur[5] - ptr_ref[5]);
sad += ABS(ptr_cur[6] - ptr_ref[6]);
sad += ABS(ptr_cur[7] - ptr_ref[7]);
ptr_cur += stride;
ptr_ref += stride;
}
Если взять за 100% всю операцию декодирования MPEG-4, то приведенный выше фрагмент кода занимает от 60 до 70% этого процессорного времени. Использование инструкций с множественными данными позволит оптимизировать данный алгоритм, так как за один такт можно выполнить несколько однотипных операций с разными входными данными.
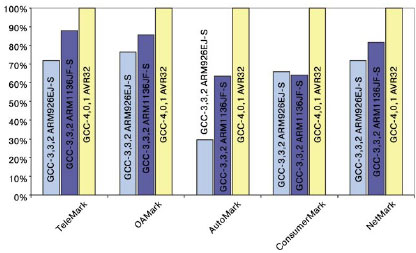
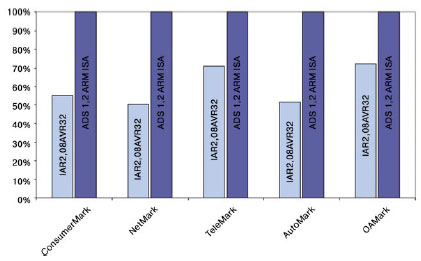
Какие результаты были достигнуты? В начале 2006 года корпорация Atmel анонсировала новое ядро AVR32 и микроконтроллер AT32AP7000 на его основе. Ядро AVR32 показало лучшие значения по производительности и энергопотреблению по сравнению с аналогичными микросхемами, ориентированными на рынок мультимедийных приложений. Так, например, алгоритм iDCT (инверсное дискретное косинусное преобразование) платформа AVR32 может выполнять на 35% быстрее, чем ядро ARM11. Такой запас можно проиллюстрировать по-другому: декодирование с частотой 30 кадров/с видеофрагмента размером "четверть" VGA (QVGA) формата MPEG-4 на платформе AVR32 может выполняться на частоте 100МГц, в то время как ARM11 сможет выполнять эту задачу только на частоте от 150МГц. При выполнении общепризнанных тестов на производительность консорциума EEMBC AVR32 демонстрирует превосходство над архитектурами ARM9 и ARM11. На рисунке 1 приведены нормализованные результаты оценки производительности AVR32, ARM11 и ARM9 (рассчитаны в условных единицах на одинаковой частоте, где большее значение на графике обозначает большую производительность).
Несомненно, разработчикам Atmel удалось создать оригинальное ядро нового поколения, способное конкурировать с лучшими микроконтроллерами для мультимедиа-приложений. Среди оригинальных нововведений разработчики кристалла выделяют следующие:
result = pointer0[offset0 >> 24] ^ pointer1[(offset1 >> 16) & 0xff] ^ pointer2[(offset2 >> 8) & 0xff] ^ (2) pointer3[offset3 & 0xff]; Выражение (2) включает четыре операции доступа к памяти, которые извлекают по одному байту в 32-разрядном слове, дополняя их нулями, и добавляют к базовому указателю. На RISC-платформах такая операция будет выполнена за 14 инструкций, в то время как AVR32 потребует в два раза меньше операций за счет использования инструкций чтения с извлечением указателя, так как все четыре операции доступа к памяти будут выполнены за 4 такта со значениями смещения (offset0..3), хранящимися в одном регистре. Для повышения эффективности операций ввода-вывода могут быть использованы команды записи в память/чтения из памяти нескольких регистров (ldm, stm). Например, они могут использоваться для быстрого возврата из подпрограмм. В этом случае, при вызове подпрограммы, команда stm будет сохранять в кэш-памяти инструкций адрес возврата, а команда ldm - извлекать его, одновременно записывая это значение в программный счетчик. Это избавит от необходимости выполнения команды возврата в конце подпрограммы.
Для экономии тактов также добавлена функция пересылки результата текущей операции на предыдущие ступени конвейера на случай, если следующая команда использует этот результат. Например, результат инструкции сложения (суммирования) в блоке ALU1 сразу пересылается на вход MUL1, ALU1 и блок адресации данных (Data Address). Это позволяет сразу воспользоваться результатом сложения и не ждать до 3-х тактов, которые потребуются для программной пересылки данных на вход конвейера. Такая функция реализована для всех инструкций AVR32.
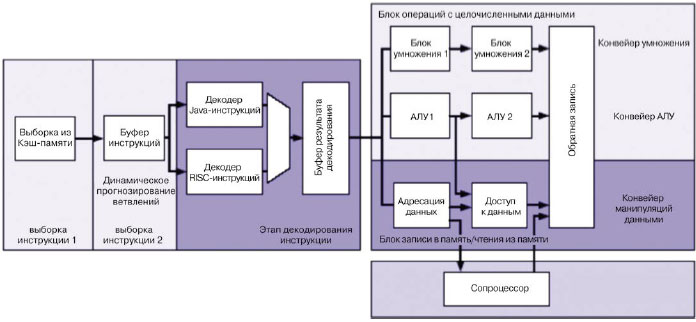
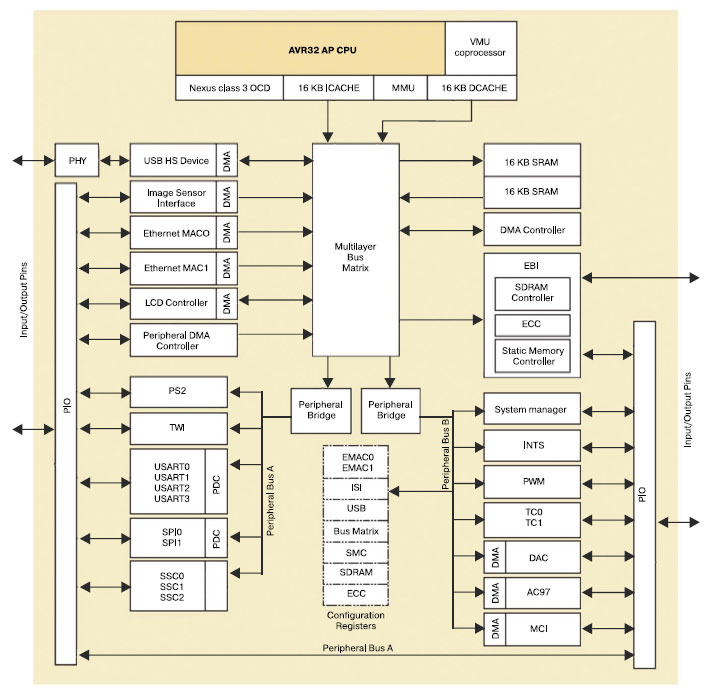
Периферийные узлы микроконтроллера AT32AP7000 Первый микроконтроллер AT32AP7000 с ядром AVR32 выпущен с набором периферийных блоков, типичным для решения мультимедийных задач. Функциональная схема AT32AP7000 изображена на рисунке 4.
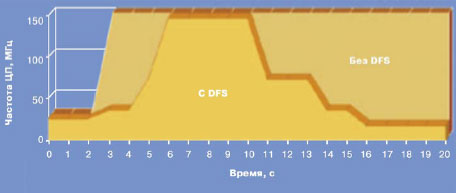
Для сбалансированной работы ядра с быстродействующей и, наоборот, медленной периферией, все периферийные блоки были ранжированы по скорости. Самые быстрые узлы (ОЗУ, интерфейс внешней памяти, High-Speed USB и т.п.) были связаны с ядром многоуровневой матрицей шин (Bus Matrix), которая обеспечивает до 16 параллельных и независимых связей между ведущими и ведомыми устройствами по шинам AHB (Advanced Host Bus). Более медленные периферийные устройства (SPI, USART0..3, аудио-ЦАП) подключены к двум шинам APB (Advanced Peripheral Bus), работающим на разных частотах. Шина APB-A имеет рабочую тактовую частоту 37.5МГц, а шина APB-B - 75МГц. Согласование скорости передачи данных между шинами APB и Bus Matrix производится мостами AHB-APB (Advanced Host Bus - Advanced Peripheral Bus). Для оптимизации энергопотребления микроконтроллера блок управления тактовой частотой (как системной, так и периферийной) имеет функцию динамического деления, которая позволяет регулировать тактовую частоту отдельно для каждой из 4-х вышеперечисленных подсистем. Такая функция полезна, когда интенсивные вычисления не производятся непрерывно во время работы микроконтроллера. Результат работы этой системы при декодировании фрагмента видеозаписи в формате MPEG-4 приведен на рисунке 5. Если принять тот факт, что ток, потребляемый микроконтроллером, пропорционален рабочей тактовой частоте, то можно сказать, что площадь на графике под кривой рабочей частоты пропорциональна энергии, потребленной за приведенный период.
Для освобождения вычислительных ресурсов ядра при операциях обмена потоковыми данными между периферией и памятью, имеется блок прямого доступа к памяти (DMA). Разработчики произвели расчет и получили, что если пересылка данных между памятью и быстродействующей периферией (USB High-Speed, Ethernet и др.) будет производиться под управлением ядра, то его свободных ресурсов для других задач просто не останется. Блок DMA в AP7000 поддерживает обмен данными не только со внутренней памятью, но и со внешней, подключенной по шине EBI (External Bus Interface). Что касается шины EBI, то по ней можно подключать различные виды памяти: SRAM, SDRAM, NAND Flash и CompactFlash. При реализации типичных математических операций при работе с изображениями могут потребоваться операции векторной математики. Они нужны для таких распространенных задач как, например, цифровой фильтрации изображений (КИХ-фильтров), преобразования его цветовой модели (RBG<->YUV) или масштабирования. Так, например, после декодирования изображения в формате MPEG-4, представленного в YUV-формате, требуется его преобразование в цветовую модель RBG, требуемую для отображения на любом дисплее. Для таких задач в микроконтроллер AP7000 включен сопроцессор для операций векторного умножения (VMU, Vector Multiplication Unit). При использовании этого блока, задача масштабирования изображения выполняется в 10 раз быстрее, чем с использованием ядра микроконтроллера. Средства разработки Как было упомянуто выше, для ядра AVR32 фирма IAR Systems разработала компилятор языка С, стоимость которого на российском рынке составит порядка 5000$. В качестве альтернативы этому коммерческому продукту предлагается бесплатный компилятор GCC, который по компактности кода проигрывает в 1.5-2 раза. В качестве аппаратного средства разработки предлагается стартовый набор STK1000 (рис.6).
В состав набора включен дистрибутив ОС Linux. Единственным на сегодняшний день недостатком построения системы на базе этой ОС является необходимость использования компилятора GCC, так как продукт IAR Systems не может компилировать проекты на основе Linux. Заключение Таким образом, разработчики фирмы Atmel реализовали в ядре AVR32 функции, позволяющие повысить производительность при решении мультимедийных задач, и в выпускающийся на базе этого ядра микроконтроллер AT32AP7000 интегрировали специализированные периферийные узлы. На сегодняшний день ядро AVR32 поддержано как коммерческими, так и бесплатными средствами разработки. В рамках небольшой обзорной статьи нельзя рассмотреть все возможности такого мощного микроконтроллера. На официальном сайте фирмы Amel размещена полная документация как на процессорное ядро AVR32, так и на микроконтроллер AT32AP7000, и есть руководства по применению с примерами программ. На форуме неофициального сайта AVR добавлен раздел, посвященный AVR32. Литература
Алексей Курилин, инженер-консультант ЭФО Статья опубликована в журнале «Электронные компоненты» №9`2006 Главная - Микросхемы - DOC - ЖКИ - Источники питания - Электромеханика - Интерфейсы - Программы - Применения - Статьи |
||||||