|
Поиск по сайту: |
|
По базе: |
| Главная страница > Статьи > Средства разработки | |||||||||
|
|
||||||||||
Форматы и секцииДистрибутив инструментария можно скачать с сайта Правильность установки проверяется командой:
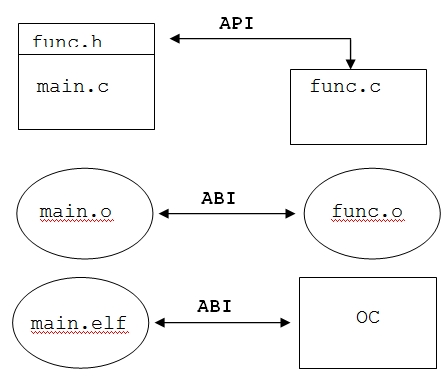
Компилятор GCC пришёл из мира UNIX. В UNIX выполнение программы начинается с создания в памяти её образа и связанных с процессом структур ядра ОС, а затем инициализации и передаче управления инструкциям программы. Программа может быть загружена в память, если она имеет специальный двоичный формат. В настоящее время большинство систем UNIX использует формат выполнения и компоновки ELF (Excecutable and Linking Format). Стандарт ELF приняли многие производители. Этот стандарт нашёл применение и в мире портативных и встраиваемых систем. Важное понятие - ABI (Application Binary Interface). В прежние времена тема ABI, не часто затрагивалась, так как как не было такого разнообразия вычислительных архитектур и операционных систем и их комбинаций. Практическая задача, нужно скомпилировать программу под смартфон, или иное портативное устройство. Совместимости на уровне API будет недостаточно, для работы программы, необходима совместимость ABI. Вопрос легко решается, если у Вас есть родной инструментарий (toolchain), который позволяет создать программу для целевой системы. Кроме того, даже имея подходящий инструментарий, нужно ещё знать, как его настроить. Для решения подобного класса задач требуется понимание принципов ABI. Интерфейс - это набор соглашений по взаимодействию. API - интерфейс для доступа к ресурсам программ, написанных на языке высокого уровня или на ассемблере. Для программ на языке C - это чаще всего заголовочные файлы. ABI - это интерфейс взаимодействия объектного файла с компоновщиком, а так же интерфейс взаимодействия исполнимого файла с операционной системой. Выражаясь точнее, порядок загрузки операционной системой исполнимого файла в память. На рисунке 1 поясняются отличия ABI от API. Интерфейс уровня ABI, находится ниже API. Подробности ABI нужно знать разработчикам компиляторов, компоновщиков и операционных систем. Но некоторые знания важны и для программистов встраиваемых систем.
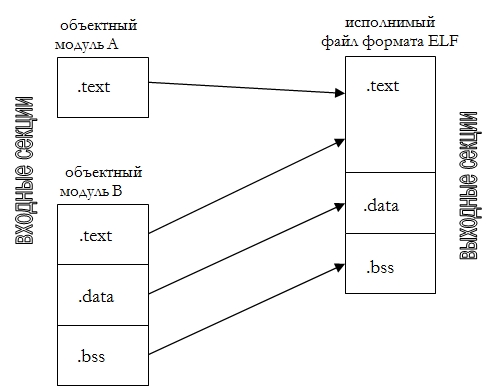
Архитектура современной вычислительной системы - это иерархия систем нескольких уровней абстракции. Программа претерпевает ряд трансформаций, от набора текстовых файлов, до процесса в памяти. Для идентификации переменных и команд на разных этапах жизненного цикла программы используются символьные имена, виртуальные адреса и физические адреса. Символьные имена присваивает программист при написании программы. Использовать символические имена и адреса вместо двоичных и восьмеричных намного удобнее. Виртуальные адреса вырабатывает транслятор. Поскольку во время трансляции не известно, в какое место памяти будет загружена программа, то виртуальным адресам присваиваются некоторые условные, промежуточные значения или они считаются не имеющими определённого значения. Физические адреса - область памяти, где в действительности будут расположены переменные и программы. Очень давно все объекты программ, размещаемых в памяти, стали делить на три категории, код, данные и не инициализированные данные. В соответствии с этим память стали делить на 3 области, где эти объекты размещали. В разных системах, эти области стали называть секциями или сегментами. Объектный файл делится на секции, содержимое некоторых секций переносится в память целевой системы. Кроме основных секций программы, в объектном файле имеется ряд секций выполняющих вспомогательные функции. Информация в этих секциях содержит указания для компоновщика, отладчика и загрузчика операционной системы. Секция text - исполнимый код, только для чтения. Секция data - инициализированные данные или секция, для чтения и записи, но не для выполнения. Секция bss - секция не инициализированных данных, допустимо чтение данных и запись в секцию. На рисунке 2 приведена схема связывания двух объектных файлов, полученных в результате трансляции. Результатом связывания будет исполнимый файл. В модуле A имеется только секция .text , а в модуле B , секции .text , .data и .bss. В процессе связывания выделяют 2 основных процесса, размещение (relocation) и разрешение символов (symbol resolution).
В данном контексте, под символом подразумевается объект программы, имеющий текстовое наименование. Переменная, определённая в тексте программы, имеет символьное обозначение, а так же этой переменной будет отведён участок памяти. В других местах программы, имеются ссылки на эту переменную, и везде эта переменная идентифицируется по символьному названию. Ясно, какую важную роль играет символьное название в процессе компоновки. Процесс связывания считается выполненным, когда разрешены все символы. Иначе говоря, когда нет ссылок на символы, расположение которых не удалось определить.
Главная - Микросхемы - DOC - ЖКИ - Источники питания - Электромеханика - Интерфейсы - Программы - Применения - Статьи |
||||||||||